转自:https://zhuanlan.zhihu.com/p/38046313
这一章主要是介绍几个简单的调度器策略。内容比较简单,就简单汇总下。
首先我们对现有的计算机环境有如下几个假设:
1.每个job都运行相同的时间。
2.所有的job都同时准备好运行
3.一旦一个job启动,那么他就会一直运行到结束。
4.所有的job都不会有I/O
5.每个job运行的时间都是可知的。
我们先引入一个效率的测量值:turnaround time
Tturnaround = Tcompletion − Tarrival
也就是任务完成时间点减去任务到达内存可以运行的时间点
一个测量反应时间的:
Tresponse = Tfirstrun − Tarrival
也就是任务第一次开始运行的时间点减去任务到达的时间点。
首先第一个策略是先入先出(First In, First Out (FIFO)),就是谁先到谁先运行。
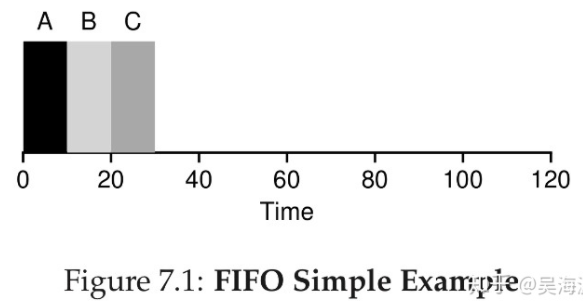
这个是一个例子,有三个任务A,B,C,我们计算对应的turnaround time为10+20+30/3=30但是如果运行时间长的任务先到,那么turnaround time就会很高,比如这个例子,
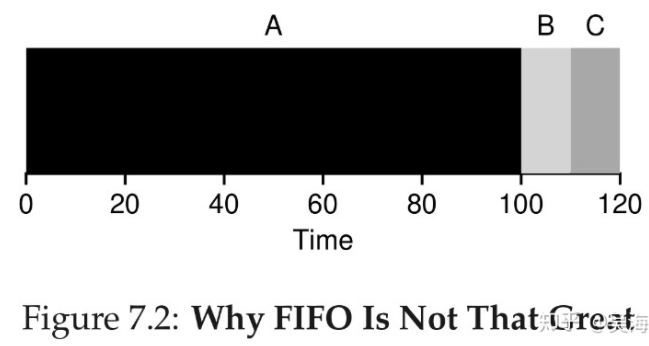
因为任务A执行时间太长,导致turnaround time为100+110+120/3=110。因此引入了下一个策略:短任务先执行(Shortest Job First (SJF))。这样会减少turnaround time。但是如果我们放开所有任务同时到达的假设,如果是长任务先来那么就还是有问题,因此引入下一个策略:运行时间短的先执行(Shortest Time-to-Completion First (STCF))。但是如果运行时间不确定那还是有问题,进一步引入了新的策略:循环执行(Round Robin)。这种策略不是让一个任务从开始执行一直到结束,而是将任务划分为固定时间的一个一个时间片,然后顺序执行,

这样对应的response time会比较好,但是turnaround time会很糟糕,可以从上面的2个对比中看出来。另外RR的这种方式还会带来任务间切换的消耗变多。而且如果进程中有I/O的时候,会导致很大的时间浪费,因此就引出了下个章节的内容:多级反馈队列(multi-level feedback queue);
1.MLFQ的的规则
我们会有一些队列,不同的队列对应不同的优先级.对于队列中的进程,调度的规则如下:
(1)如果Priority(A) > Priority(B),那么A运行。
(2)如果Priority(A) = Priority(B),那么A,B按照Round-Robin方式运行。
(3)当一个任务创立的是时候,它在最高的优先级中
(4a)如果一个任务执行的时候消耗了整个时间片,那么降低优先级
(4b)如果一个任务主动放弃cpu的执行时间,那么保持优先级不变
上面的规则所构成的调度规则,会有如下的问题:
(1)如果有很多的job是交互性的,那么会导致那些需要大量cpu时间的job无法运行
(2)不公平性。如果有些job写的时候故意在时间片的最后一点时间放弃cpu,那么他就可以一直保持一个高优先级的状态。
(3)上面的规则只规定了job的优先级下降,但是如果一个job 从耗费cpu变为了交互性,它的优先级也是没办法提高的。
所以对上面的规则又新增了一些规则:
(5)经过一个时间S后,将所有的任务都调整到权限最高的队列。
(6)对规则4a和4b进行修改,一个job使用完该等级上的时间后,就会降低它的优先级。
上面的这些规则中包含了很多的设置内容,比如队列的个数,时间片的时间,调整所有低优先级job的时间,每个队列对应的时间为多少等等,这些都是具体在实现MLFQ的时候需要考虑的,一个好的建议是这些数值能够可配置化,避免写死。
上面介绍的调度策略在多核的时代还能不能适用呢?
首先什么是多核,就是因为单核的速度无法提升,所以只能以增加核心的方式来提升cpu 的速度。而且需要注意的是每个核心都有对应的缓存,所以这个会导致缓存不一致的情况。另外还需要考虑的就是并发的问题,这个可以通过加锁机制来完成。另外对于多核来说,会带来一个新的问题,那就是缓存关联性(Cache Affinity)。也就是说,如果一个进程如果能够一直运行在一个核上,那么就可以利用高速缓存来提高运行的效率,反之运行速度就会低下。
对于多核的OS调度机制,可以有两种方案,一种是单个调度队列(SQMS:single queue multiprocessor scheduling),一种是每个核一个调度队列(multi-queue multiprocessor scheduling (or MQMS))。
SQMS的优势在于能够简单,能够直接应用之前的调度代码。弊端也显而易见,首先是效率的问题,因为一个队列表示需要大量的锁操作来实现对数据的正确访问。其次缓存关联性问题也很突出,不过也有一些解决方案,比如固定一些进程只在某个核上跑,另外的则在多个核之前轮转的运行。
MQMS对于每个核都有一个调度的队列,这保证了扩展性,并发不是公用锁,所以效率也得到提升。但是会牵扯出负载均衡的问题。首先是怎么决定新生成的进程应该属于哪个队列,其次是如果核之间的任务数量失衡,怎么补救。第一个问题我们用启发式的方法决定,第二个可以使用进程在队列间的移动。再来个问题,每个核如何发现其他核的情况呢,那么肯定就需要去访问对应核的内核数据结构,这个频率不应该太高,也不应该太低,具体的就需要在实现的时候考虑了。所以实际的策略实现中,都需要大量的trade-off,因为在实际的场景中,没有一个最优的答案,有的只是不断探索然后将方案做到尽可能好。
最后对于linux来说,对多核是有多个调度器策略的。O(1), CFS , BFS,这个就不做介绍了。