1. 配置文件介绍
Canal的启动,是以创建实例(instance)的方式,每个实例都有自己单独的工作环境,
而配置也分成两个部分
- canal.properties (系统根配置文件)
- instance.properties (instance级别的配置文件,每个instance一份)
1.1 canal.properties常用配置介绍:
1.instance列表定义
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.destinations | 当前server上部署的instance列表 | 无 |
| canal.conf.dir | conf/目录所在的路径 | ../conf |
| canal.auto.scan | 开启instance自动扫描 如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发: a. instance目录新增: 触发instance配置载入,lazy为true时则自动启动 b. instance目录删除:卸载对应instance配置,如已启动则进行关闭 c. instance.properties文件变化:reload instance配置,如已启动自动进行重启操作 | true |
| canal.auto.scan.interval | instance自动扫描的间隔时间,单位秒 | 5 |
| canal.instance.global.mode | 全局配置加载方式 | spring |
| canal.instance.global.lazy | 全局lazy模式 | false |
| canal.instance.global.manager.address | 全局的manager配置方式的链接信息 | 无 |
| canal.instance.global.spring.xml | 全局的spring配置方式的组件文件 | classpath:spring/memory-instance.xml (spring目录相对于canal.conf.dir) |
| canal.instance.example.mode canal.instance.example.lazy canal.instance.example.spring.xml ….. | instance级别的配置定义,如有配置,会自动覆盖全局配置定义模式 命名规则:canal.instance.{name}.xxx | 无 |
| canal.instance.tsdb.spring.xml | v1.0.25版本新增,全局的tsdb配置方式的组件文件 | classpath:spring/tsdb/h2-tsdb.xml (spring目录相对于canal.conf.dir) |
2.common参数定义,比如可以将instance.properties的公用参数,抽取放置到这里,这样每个instance启动的时候就可以共享.(instance.properties配置定义优先级高于canal.properties)
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.id | 每个canal server实例的唯一标识,暂无实际意义 | 1 |
| canal.ip | canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务 | 无 |
| canal.register.ip | canal server注册到外部zookeeper、admin的ip信息 (针对docker的外部可见ip) | 无 |
| canal.port | canal server提供socket服务的端口 | 11111 |
| canal.zkServers | canal server链接zookeeper集群的链接信息 例子:10.20.144.22:2181,10.20.144.51:2181 | 无 |
| canal.zookeeper.flush.period | canal持久化数据到zookeeper上的更新频率,单位毫秒 | 1000 |
| canal.instance.memory.batch.mode | canal内存store中数据缓存模式 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小 | MEMSIZE |
| canal.instance.memory.buffer.size | canal内存store中可缓存buffer记录数,需要为2的指数 | 16384 |
| canal.instance.memory.buffer.memunit | 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小 | 1024 |
| canal.instance.transactionn.size | 最大事务完整解析的长度支持 超过该长度后,一个事务可能会被拆分成多次提交到canal store中,无法保证事务的完整可见性 | 1024 |
| canal.instance.fallbackIntervalInSeconds | canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒 说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢 | 60 |
| canal.instance.detecting.enable | 是否开启心跳检查 | false |
| canal.instance.detecting.sql | 心跳检查sql | insert into retl.xdual values(1,now()) on duplicate key update x=now() |
| canal.instance.detecting.interval.time | 心跳检查频率,单位秒 | 3 |
| canal.instance.detecting.retry.threshold | 心跳检查失败重试次数 | 3 |
| canal.instance.detecting.heartbeatHaEnable | 心跳检查失败后,是否开启自动mysql自动切换 说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据 | false |
| canal.instance.network.receiveBufferSize | 网络链接参数,SocketOptions.SO_RCVBUF | 16384 |
| canal.instance.network.sendBufferSize | 网络链接参数,SocketOptions.SO_SNDBUF | 16384 |
| canal.instance.network.soTimeout | 网络链接参数,SocketOptions.SO_TIMEOUT | 30 |
| canal.instance.filter.druid.ddl | 是否使用druid处理所有的ddl解析来获取库和表名 | true |
| canal.instance.filter.query.dcl | 是否忽略dcl语句 | false |
| canal.instance.filter.query.dml | 是否忽略dml语句 (mysql5.6之后,在row模式下每条DML语句也会记录SQL到binlog中,可参考MySQL文档) | false |
| canal.instance.filter.query.ddl | 是否忽略ddl语句 | false |
| canal.instance.filter.table.error | 是否忽略binlog表结构获取失败的异常(主要解决回溯binlog时,对应表已被删除或者表结构和binlog不一致的情况) | false |
| canal.instance.filter.rows | 是否dml的数据变更事件(主要针对用户只订阅ddl/dcl的操作) | false |
| canal.instance.filter.transaction.entry | 是否忽略事务头和尾,比如针对写入kakfa的消息时,不需要写入TransactionBegin/Transactionend事件 | false |
| canal.instance.binlog.format | 支持的binlog format格式列表 (otter会有支持format格式限制) | ROW,STATEMENT,MIXED |
| canal.instance.binlog.image | 支持的binlog image格式列表 (otter会有支持format格式限制) | FULL,MINIMAL,NOBLOB |
| canal.instance.get.ddl.isolation | ddl语句是否单独一个batch返回(比如下游dml/ddl如果做batch内无序并发处理,会导致结构不一致) | false |
| canal.instance.parser.parallel | 是否开启binlog并行解析模式(串行解析资源占用少,但性能有瓶颈, 并行解析可以提升近2.5倍+) | true |
| canal.instance.parser.parallelBufferSize | binlog并行解析的异步ringbuffer队列 (必须为2的指数) | 256 |
| canal.instance.tsdb.enable | 是否开启tablemeta的tsdb能力 | true |
| canal.instance.tsdb.dir | 主要针对h2-tsdb.xml时对应h2文件的存放目录,默认为conf/xx/h2.mv.db | ${canal.file.data.dir:../conf}/${canal.instance.destination:} |
| canal.instance.tsdb.url | jdbc url的配置(h2的地址为默认值,如果是mysql需要自行定义) | jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; |
| canal.instance.tsdb.dbUsername | jdbc url的配置(h2的地址为默认值,如果是mysql需要自行定义) | canal |
| canal.instance.tsdb.dbPassword | jdbc url的配置(h2的地址为默认值,如果是mysql需要自行定义) | canal |
| canal.instance.rds.accesskey | aliyun账号的ak信息(如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值 | 无 |
| canal.instance.rds.secretkey | aliyun账号的sk信息(如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值) | 无 |
| canal.admin.manager | canal链接canal-admin的地址 (v1.1.4新增) | 无 |
| canal.admin.port | admin管理指令链接端口 (v1.1.4新增) | 11110 |
| canal.admin.user | admin管理指令链接的ACL配置 (v1.1.4新增) | admin |
| canal.admin.passwd | admin管理指令链接的ACL配置 (v1.1.4新增) | 密码默认值为admin的密文 |
| canal.user | canal数据端口订阅的ACL配置 (v1.1.4新增)如果为空,代表不开启 | 无 |
| canal.passwd | canal数据端口订阅的ACL配置 (v1.1.4新增)如果为空,代表不开启 | 无 |
1.2 instance.properties常用配置介绍
在canal.properties定义了canal.destinations后,需要在canal.conf.dir对应的目录下建立同名的文件
比如:
canal.destinations = example1,example2
这时需要创建example1和example2两个目录,每个目录里各自有一份instance.properties.
instance.properties参数列表:
| 参数名字 | 参数说明 | 默认值 |
|---|---|---|
| canal.instance.mysql.slaveId | mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定) | 无 |
| canal.instance.master.address | mysql主库链接地址 | 127.0.0.1:3306 |
| canal.instance.master.journal.name | mysql主库链接时起始的binlog文件 | 无 |
| canal.instance.master.position | mysql主库链接时起始的binlog偏移量 | 无 |
| canal.instance.master.timestamp | mysql主库链接时起始的binlog的时间戳 | 无 |
| canal.instance.gtidon | 是否启用mysql gtid的订阅模式 | false |
| canal.instance.master.gtid | mysql主库链接时对应的gtid位点 | 无 |
| canal.instance.dbUsername | mysql数据库帐号 | canal |
| canal.instance.dbPassword | mysql数据库密码 | canal |
| canal.instance.defaultDatabaseName | mysql链接时默认schema | |
| canal.instance.connectionCharset | mysql 数据解析编码 | UTF-8 |
| canal.instance.filter.regex | mysql 数据解析关注的表,Perl正则表达式.多个正则之间以逗号(,)分隔,转义符需要双斜杠() 常见例子:1. 所有表:.* or ... 2. canal schema下所有表: canal..* 3. canal下的以canal打头的表:canal.canal.* 4. canal schema下的一张表:canal.test15. 多个规则组合使用:canal..*,mysql.test1,mysql.test2 (逗号分隔) | ... |
| canal.instance.filter.black.regex | mysql 数据解析表的黑名单,表达式规则见白名单的规则 | 无 |
| canal.instance.rds.instanceId | aliyun rds对应的实例id信息(如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值) | 无 |
2. 连接MQ
2.1 配置信息
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
- kafka
- RocketMQ
本文将使用RocketMQ,具体使用可以参考这篇博文: https://www.cnblogs.com/xjwhaha/p/15055452.html
修改相关配置:
canal.properties文件修改:
#指定消息投递方式为 RocketMQ, 默认为TCP,即客户端连接的方式
canal.serverMode = RocketMQ
#指定mq地址
canal.mq.servers = 192.168.3.88:9876
instance.properties文件修改:
# 消费组名
canal.mq.producerGroup = test_group
# 投递的topic
canal.mq.topic=test_topic
#也可指定动态生成的topic,例如根据 库名_表名 投递
#canal.mq.dynamicTopic=.*\..*
更加详细的配置信息参考如下:
| 参数名 | 参数说明 | 默认值 |
|---|---|---|
| canal.mq.servers | kafka为bootstrap.servers rocketMQ中为nameserver列表 | 127.0.0.1:6667 |
| canal.mq.retries | 发送失败重试次数 | 0 |
| canal.mq.batchSize | kafka为ProducerConfig.BATCH_SIZE_CONFIG rocketMQ无意义 |
16384 |
| canal.mq.maxRequestSize | kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIG rocketMQ无意义 |
1048576 |
| canal.mq.lingerMs | kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200 rocketMQ无意义 |
1 |
| canal.mq.bufferMemory | kafka为ProducerConfig.BUFFER_MEMORY_CONFIG rocketMQ无意义 |
33554432 |
| canal.mq.acks | kafka为ProducerConfig.ACKS_CONFIG rocketMQ无意义 |
all |
| canal.mq.kafka.kerberos.enable | kafka为ProducerConfig.ACKS_CONFIG rocketMQ无意义 |
false |
| canal.mq.kafka.kerberos.krb5FilePath | kafka kerberos认证 rocketMQ无意义 | ../conf/kerberos/krb5.conf |
| canal.mq.kafka.kerberos.jaasFilePath | kafka kerberos认证 rocketMQ无意义 | ../conf/kerberos/jaas.conf |
| canal.mq.producerGroup | kafka无意义 rocketMQ为ProducerGroup名 | Canal-Producer |
| canal.mq.accessChannel | kafka无意义 rocketMQ为channel模式,如果为aliyun则配置为cloud | local |
| — | — | — |
| canal.mq.vhost= | rabbitMQ配置 | 无 |
| canal.mq.exchange= | rabbitMQ配置 | 无 |
| canal.mq.username= | rabbitMQ配置 | 无 |
| canal.mq.password= | rabbitMQ配置 | 无 |
| canal.mq.aliyunuid= | rabbitMQ配置 | 无 |
| — | — | — |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.parallelThreadSize | mq数据转换并行处理的并发度 | 8 |
| canal.mq.flatMessage | 是否为json格式 如果设置为false,对应MQ收到的消息为protobuf格式 需要通过CanalMessageDeserializer进行解码 | false |
| — | — | — |
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.partitionHash | 散列规则定义 库名.表名 : 唯一主键,比如mytest.person: id 1.1.3版本支持新语法,见下文 | 无 |
canal.mq.dynamicTopic 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:... 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:... 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test..* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:...:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:...:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:... ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- 按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test.test:id,…* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
2.2 启动canal
启动canal成功后,可以查看RocketMQ 管理平台,已经创建了对应的topic,

并且在修改数据库后,也发送了相应的消息:

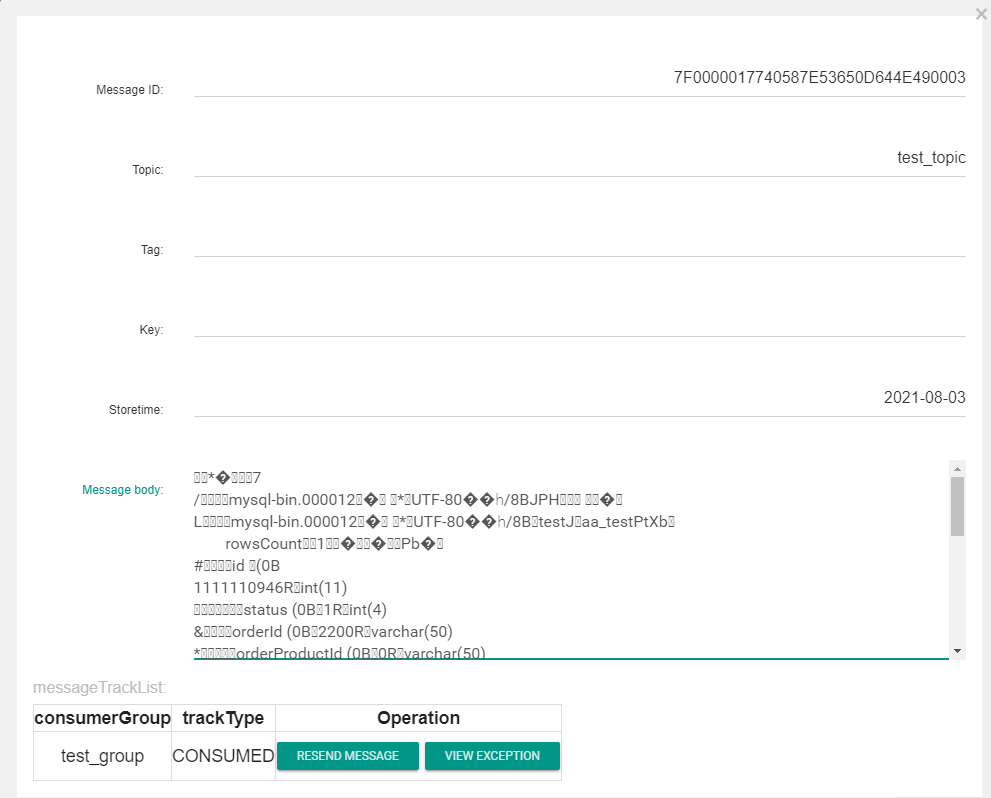
查看消息体,根据配置信息canal.mq.flatMessage 的不同, 消息体表现为不同的形式, 分别为二进制,和json的形式,如果没有必要可以 设置为false,提高性能
二进制:
json:
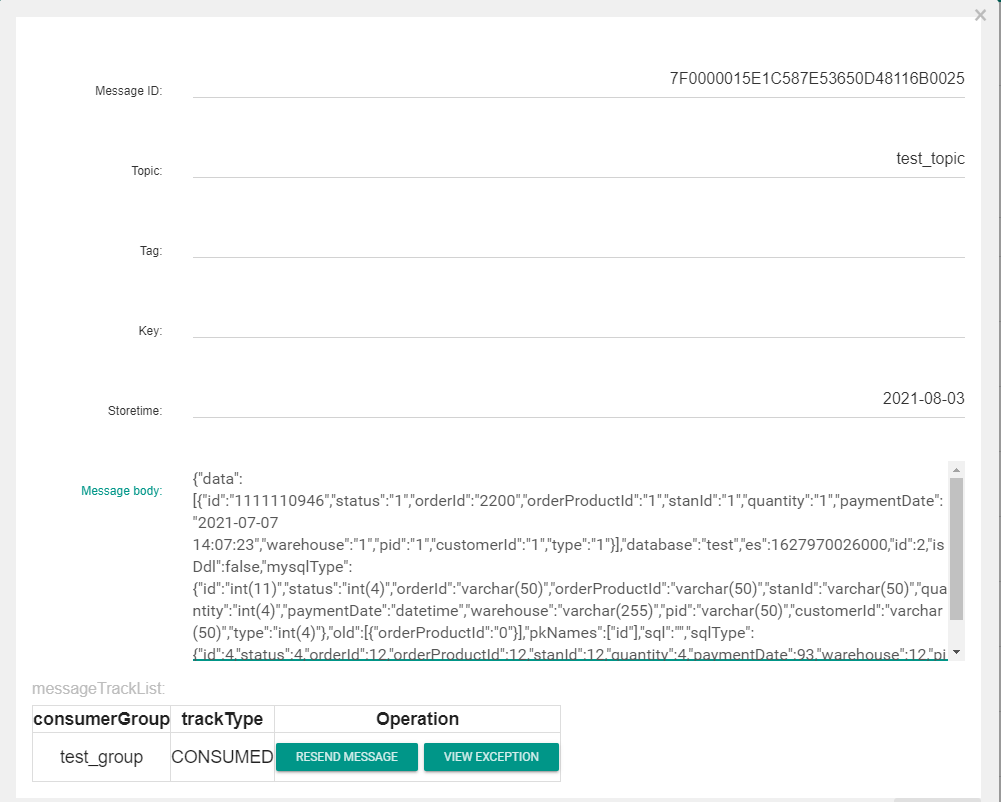
2.3 消费端
当开启MQ形式后,就不能使用原来的方式去操作数据的变化,而是使用对应MQ的消费方式,例如:
public class Consumer {
public static void main(String[] args) throws Exception {
// 实例化消息生产者,指定组名
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("test_group");
// 指定Namesrv地址信息.
consumer.setNamesrvAddr("192.168.3.244:9876");
// 订阅Topic
consumer.subscribe("test_topic", "*");
//负载均衡模式消费
consumer.setMessageModel(MessageModel.CLUSTERING);
// 注册回调函数,处理消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n",
Thread.currentThread().getName(), msgs);
for (MessageExt messageExt : msgs) {
byte[] data = messageExt.getBody();
if (data != null) {
Message message = CanalMessageDeserializer.deserializer(data);
// 如果canal配置 canal.mq.flatMessage = true,则以json方式解析
// FlatMessage flatMessage = JSON.parseObject(data, FlatMessage.class);
printEntry(message.getEntries());
}
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//启动消息者
consumer.start();
System.out.printf("Consumer Started.%n");
}
private static void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
//如果是事务开启关闭时间则跳过
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage = null;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
结合RocketMQ 的消费方式和 alibaba 的ottr包进行解析信息,可以对将消费封装为对象:
依赖:
<dependencies>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.5</version>
</dependency>
</dependencies>
修改数据库信息,打印信息如下:
================> binlog[mysql-bin.000012:3587] , name[test,aa_test] , eventType : UPDATE
-------> before
id : 1111110946 update=false
status : 1 update=false
orderId : 2200 update=false
orderProductId : 0 update=false
stanId : 1 update=false
quantity : 1 update=false
paymentDate : 2021-07-07 14:07:23 update=false
warehouse : 1 update=false
pid : 1 update=false
customerId : 1 update=false
type : 1 update=false
-------> after
id : 1111110946 update=false
status : 1 update=false
orderId : 2200 update=false
orderProductId : 1 update=true
stanId : 1 update=false
quantity : 1 update=false
paymentDate : 2021-07-07 14:07:23 update=false
warehouse : 1 update=false
pid : 1 update=false
customerId : 1 update=false
type : 1 update=false
3. 启动源码探究
在指定canal.serverMode = rocketMQ 后,数据的消费方式为 MQ方式,此时 使用客户端链接的方式将无法使用
会报如下错误: Connection refused: connect
因为服务端没有开启Netty相关服务,下面查看源码,探究是如何启动的
Canal的启动入口为CanalLauncher 类的main方法,
public class CanalLauncher {
// ....
public static void main(String[] args) {
try {
logger.info("## set default uncaught exception handler");
setGlobalUncaughtExceptionHandler();
logger.info("## load canal configurations");
//解析配置文件
String conf = System.getProperty("canal.conf", "classpath:canal.properties");
Properties properties = new Properties();
if (conf.startsWith(CLASSPATH_URL_PREFIX)) {
conf = StringUtils.substringAfter(conf, CLASSPATH_URL_PREFIX);
properties.load(CanalLauncher.class.getClassLoader().getResourceAsStream(conf));
} else {
properties.load(new FileInputStream(conf));
}
//将配置信息赋予 启动类
final CanalStarter canalStater = new CanalStarter(properties);
String managerAddress = CanalController.getProperty(properties, CanalConstants.CANAL_ADMIN_MANAGER);
if (StringUtils.isNotEmpty(managerAddress)) {
String user = CanalController.getProperty(properties, CanalConstants.CANAL_ADMIN_USER);
String passwd = CanalController.getProperty(properties, CanalConstants.CANAL_ADMIN_PASSWD);
String adminPort = CanalController.getProperty(properties, CanalConstants.CANAL_ADMIN_PORT, "11110");
boolean autoRegister = BooleanUtils.toBoolean(CanalController.getProperty(properties,
CanalConstants.CANAL_ADMIN_AUTO_REGISTER));
String autoCluster = CanalController.getProperty(properties, CanalConstants.CANAL_ADMIN_AUTO_CLUSTER);
String registerIp = CanalController.getProperty(properties, CanalConstants.CANAL_REGISTER_IP);
if (StringUtils.isEmpty(registerIp)) {
registerIp = AddressUtils.getHostIp();
}
final PlainCanalConfigClient configClient = new PlainCanalConfigClient(managerAddress,
user,
passwd,
registerIp,
Integer.parseInt(adminPort),
autoRegister,
autoCluster);
PlainCanal canalConfig = configClient.findServer(null);
if (canalConfig == null) {
throw new IllegalArgumentException("managerAddress:" + managerAddress
+ " can't not found config for [" + registerIp + ":" + adminPort
+ "]");
}
Properties managerProperties = canalConfig.getProperties();
// merge local
managerProperties.putAll(properties);
int scanIntervalInSecond = Integer.valueOf(CanalController.getProperty(managerProperties,
CanalConstants.CANAL_AUTO_SCAN_INTERVAL,
"5"));
executor.scheduleWithFixedDelay(new Runnable() {
private PlainCanal lastCanalConfig;
public void run() {
try {
if (lastCanalConfig == null) {
lastCanalConfig = configClient.findServer(null);
} else {
PlainCanal newCanalConfig = configClient.findServer(lastCanalConfig.getMd5());
if (newCanalConfig != null) {
// 远程配置canal.properties修改重新加载整个应用
canalStater.stop();
Properties managerProperties = newCanalConfig.getProperties();
// merge local
managerProperties.putAll(properties);
canalStater.setProperties(managerProperties);
canalStater.start();
lastCanalConfig = newCanalConfig;
}
}
} catch (Throwable e) {
logger.error("scan failed", e);
}
}
}, 0, scanIntervalInSecond, TimeUnit.SECONDS);
canalStater.setProperties(managerProperties);
} else {
canalStater.setProperties(properties);
}
//已上的代码都是在解析配置文件,为接下来的启动做准备
//启动
canalStater.start();
runningLatch.await();
executor.shutdownNow();
} catch (Throwable e) {
logger.error("## Something goes wrong when starting up the canal Server:", e);
}
}
// ....
}
接下来看 canalStart的start方法:
public synchronized void start() throws Throwable {
//这里获取的就是 canal.serverMode 的配置信息
//可以看出如果配置 为 kafaka 或者 rocketmq 则会对对应的生产对象初始化
String serverMode = CanalController.getProperty(properties, CanalConstants.CANAL_SERVER_MODE);
if (serverMode.equalsIgnoreCase("kafka")) {
canalMQProducer = new CanalKafkaProducer();
} else if (serverMode.equalsIgnoreCase("rocketmq")) {
canalMQProducer = new CanalRocketMQProducer();
}
//如果 MQ 生产对象不为空
if (canalMQProducer != null) {
// 设置禁用Netty 标识
System.setProperty(CanalConstants.CANAL_WITHOUT_NETTY, "true");
// 设置为raw避免ByteString->Entry的二次解析
System.setProperty("canal.instance.memory.rawEntry", "false");
}
logger.info("## start the canal server.");
// 初始化 canal server 主控制类
controller = new CanalController(properties);
controller.start();
logger.info("## the canal server is running now ......");
shutdownThread = new Thread() {
public void run() {
try {
logger.info("## stop the canal server");
controller.stop();
CanalLauncher.runningLatch.countDown();
} catch (Throwable e) {
logger.warn("##something goes wrong when stopping canal Server:", e);
} finally {
logger.info("## canal server is down.");
}
}
};
Runtime.getRuntime().addShutdownHook(shutdownThread);
// 初始化 canalMQStarter , 并赋予给 总控制类CanalController
if (canalMQProducer != null) {
canalMQStarter = new CanalMQStarter(canalMQProducer);
MQProperties mqProperties = buildMQProperties(properties);
String destinations = CanalController.getProperty(properties, CanalConstants.CANAL_DESTINATIONS);
canalMQStarter.start(mqProperties, destinations);
controller.setCanalMQStarter(canalMQStarter);
}
// start canalAdmin
String port = properties.getProperty(CanalConstants.CANAL_ADMIN_PORT);
if (canalAdmin == null && StringUtils.isNotEmpty(port)) {
String user = properties.getProperty(CanalConstants.CANAL_ADMIN_USER);
String passwd = properties.getProperty(CanalConstants.CANAL_ADMIN_PASSWD);
CanalAdminController canalAdmin = new CanalAdminController(this);
canalAdmin.setUser(user);
canalAdmin.setPasswd(passwd);
String ip = properties.getProperty(CanalConstants.CANAL_IP);
CanalAdminWithNetty canalAdminWithNetty = CanalAdminWithNetty.instance();
canalAdminWithNetty.setCanalAdmin(canalAdmin);
canalAdminWithNetty.setPort(Integer.valueOf(port));
canalAdminWithNetty.setIp(ip);
canalAdminWithNetty.start();
this.canalAdmin = canalAdminWithNetty;
}
running = true;
}
而在 controller = new CanalController(properties); 这步初始化 Canal控制类时,则读取标识信息,判断是否启动Netty服务:
// ...
String canalWithoutNetty = getProperty(properties, CanalConstants.CANAL_WITHOUT_NETTY);
if (canalWithoutNetty == null || "false".equals(canalWithoutNetty)) {
canalServer = CanalServerWithNetty.instance();
canalServer.setIp(ip);
canalServer.setPort(port);
}
// ...
最后在最终的启动方法中:controller.start(),因为 canalServer 为空,则没有启动Netty Server服务
// ...
// 启动网络接口
if (canalServer != null) {
canalServer.start();
}
// ..