导语:
把所有的数据都存放于一张表的弊端
1:表的组织结构复杂不清晰
2:浪费空间
3:扩展性极差
一、 寻找表与表之间的关系套路:
举例:emp 员工表 dep 部门表
步骤:
part1:
1、先站在左表 emp 的角度
2、去找左表emp 的多条记录能否对应右表dep的一条记录
3、翻译2 的意义:
左表emp 的多条记录==》》多个员工
右表dep 的一条记录==》》一个部门
最终的翻译结果:多个员工是否可以属于同一个部门?
如果是则需要进行part2 的流程
part2:
1、先站在右表dep 的角度
2、去找右表dep 的多条记录能否对应左表emp的一条记录
3、翻译2 的意义:
右表dep的多条记录==》》多个员工
左表emp 的一条记录==》》一个部门
最终的翻译结果:多个部门是否可以包含同一个员工
如果不可以, 则可以确定emp与dep的 关系只一个单向的多对一
如何实现?
在emp表中新增一个dep_id 字段, 该字段指向dep表的id字段
配图:

用foreign key 来实现 多对一
约束1:在创建表时, 先创建被关联的表dep(也就是多对一中的一),在创建关联表emp(多对一的多),否则就会报错
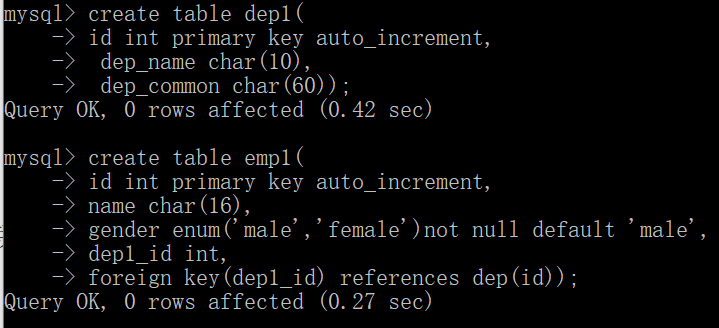
约束2:在插入记录时, 必须先插被关的表dep,才能插关联表emp,否则也会报错

3:约束3:更新与删除都需要考虑到关联与被关联的关系
1:先删除关联表emp1,再删除被关联表dep1, 否则也会报错
2:重建:新增功能,同步更新, 同步删除 用on update cascade on delete cascade
先创建:

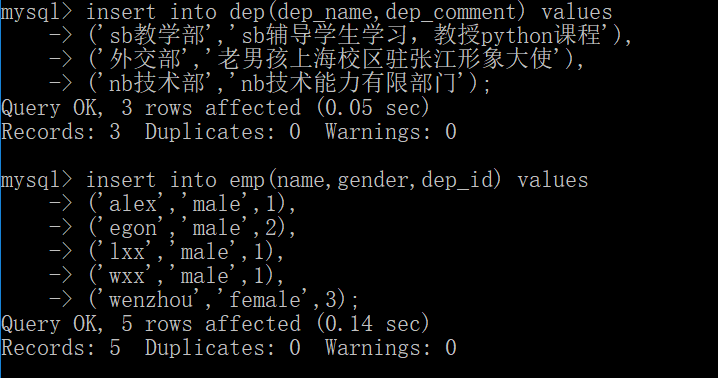
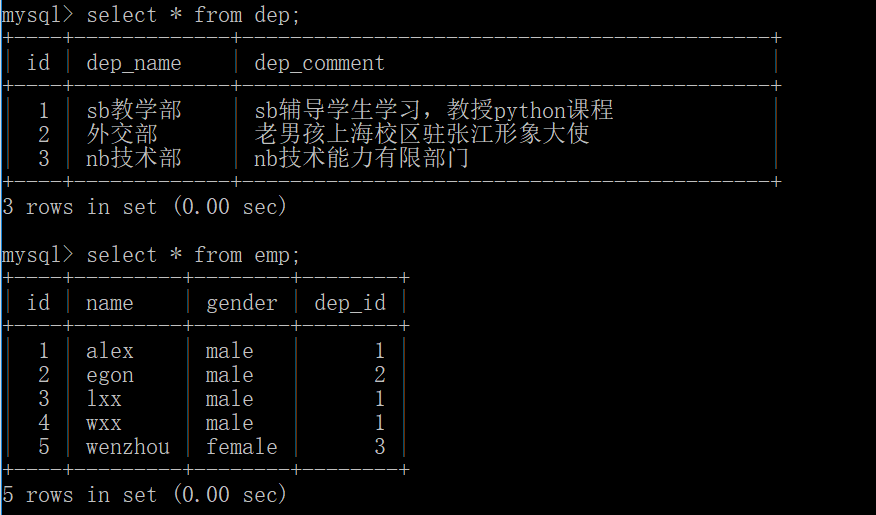
查询数据:
同步删除:delete from 表名 where + 条件

同步更新:update 表名 set 更改内容 where +条件
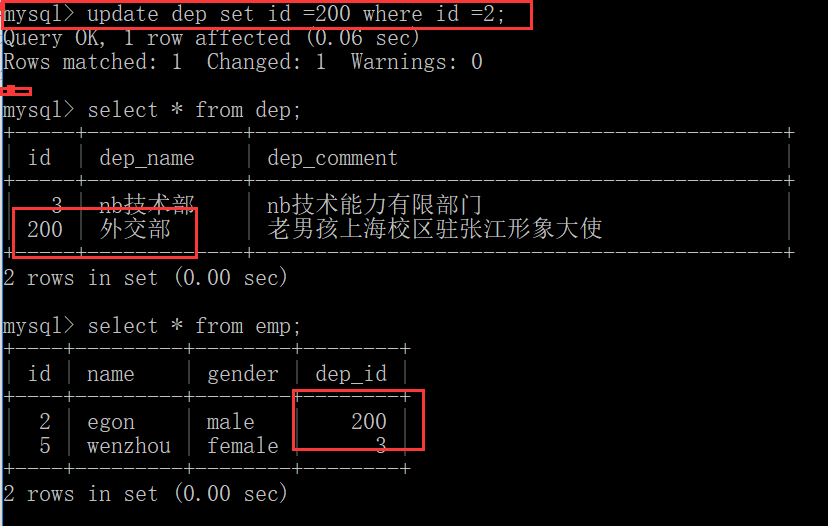
清空表:delete from tb1
q强调;上面这条命令确实可以将表里的记录都删掉, 但是不会将id重置为0,
所有该条命令根本不是用来清空表的, delete是用来删除表中某一些符合条件的记录
delete from tb1 where id >10;
如果要清空表 要使用truncate tb1;
作用是将整张表重置。
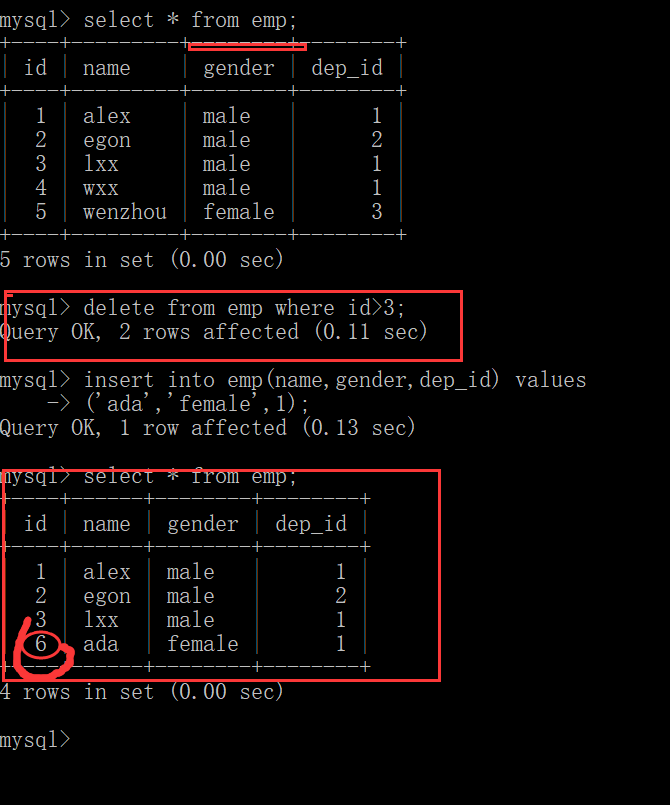
如图:删掉id>3 以上的数据后 在添加新的数据, 是在原来没有删除的id的基础上添加。所以这时不应该用 delete.
二:多对多
两张表之间是一个双向的多对一关系,称之为多对多
如何实现
建立第3张表,该表中有一个字段fk 左表的id,还有一个字段fk 右表的id
例如:两张表, 一个书表,一个作者表:
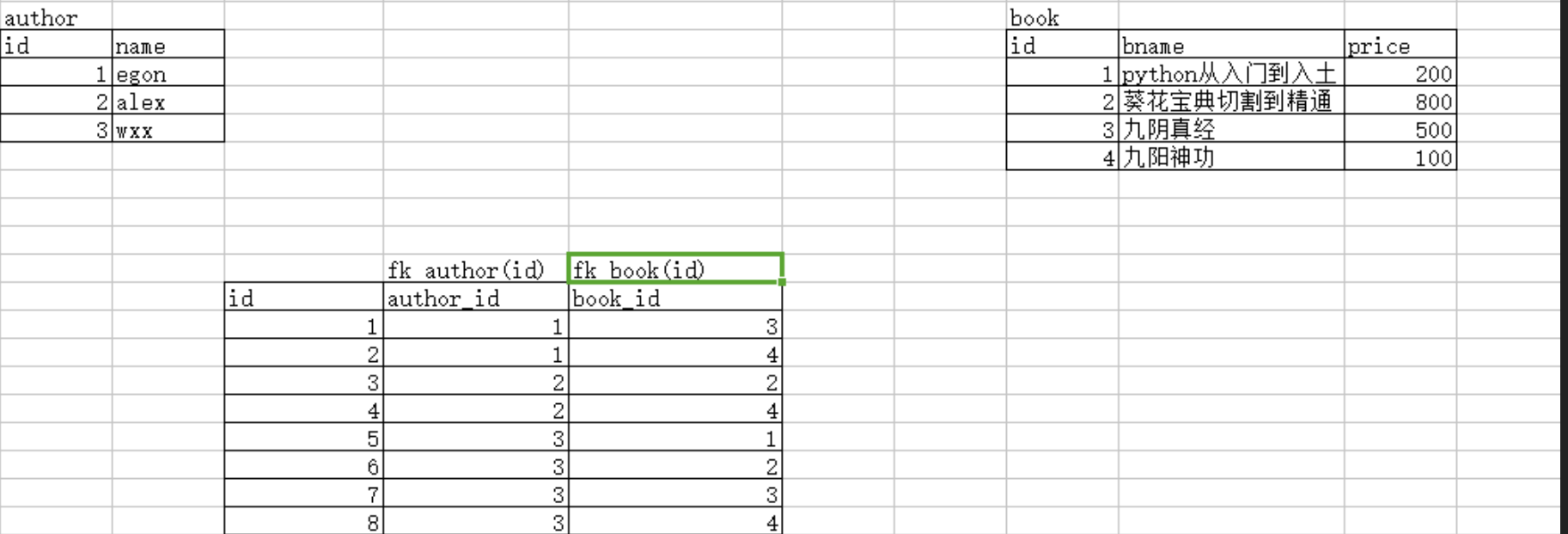
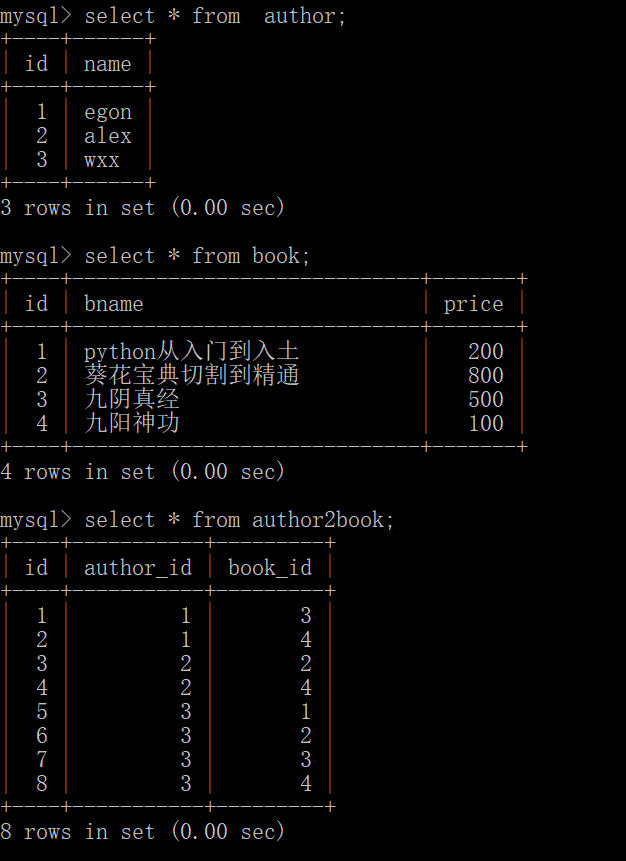
首先创造出这两张表:
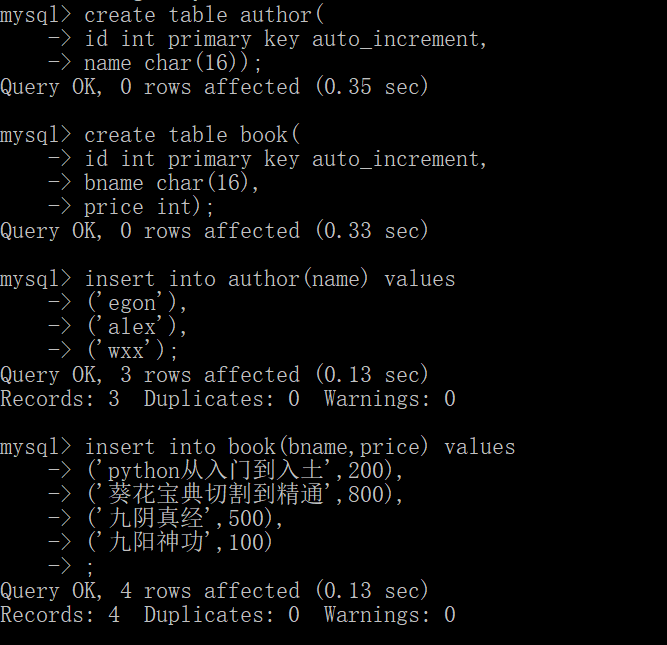
现在创造第3张表
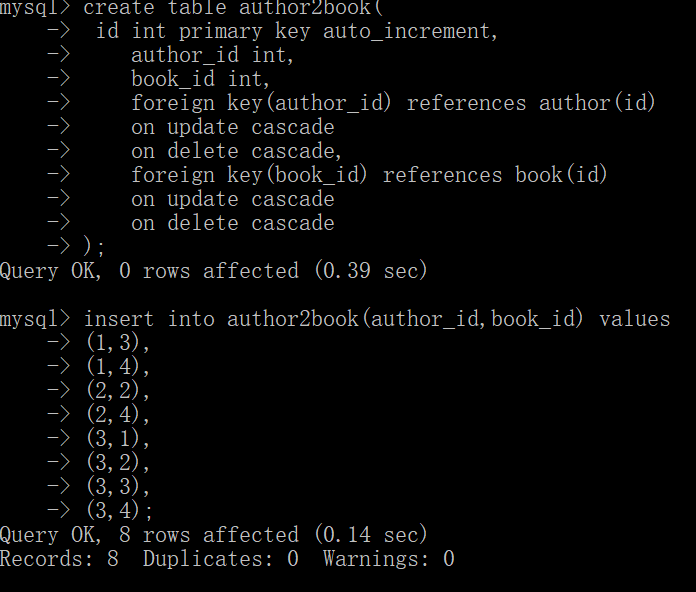
查询:
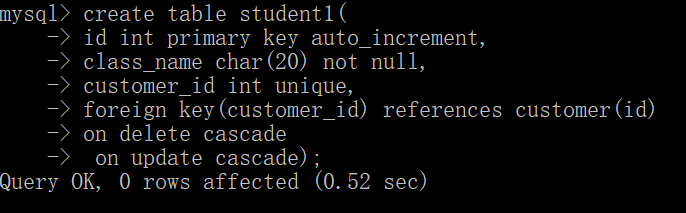
一对一
左表的一条记录唯一对应右表的一条记录,反之也一样,
这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
配图:

张铁蛋 李大炮 杨力 赵子弹 刘二丫 王三炮 alex 梁树东
创建表

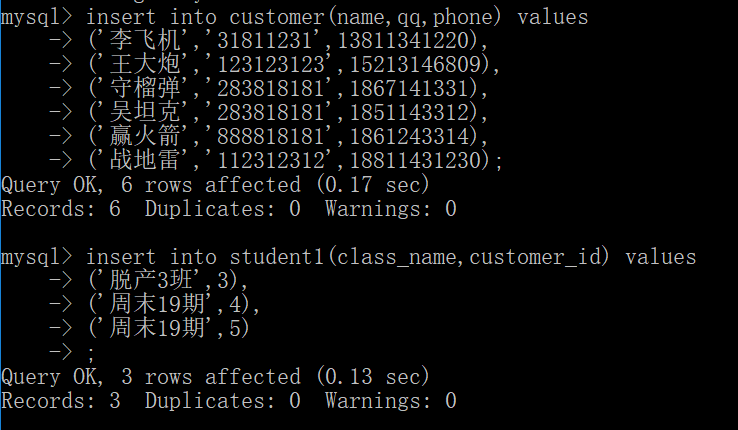
插入数据:
查数据:
