2010年, 美国的云计算公司 Rackspace 想重写他们的云平台代码, 并打算开源他们的技术和代码; 与此同时, NASA(美国航空航天局)下属的 Anso Lab 实验室发布了他们的 Beta 版的云计算平台代码;
Rackspace 想和 NASA 共同成立一个开源的云计算平台项目;
2010年7月, 在奥斯丁, Rackspace 和 NASA 一起创建了 OpenStack 项目, 之后在波特兰的世界开源大会上, OpenStack 被正式宣布;
开源之后, 大部分公司都选择了 OpenStack 作为自己的云计算平台, 国内使用 OpenStack 的公司有 腾讯, 阿里, 百度, 华为, 中国移动等等;
根据 Galera 的用户案例里面的描述, 中国移动使用 OpenStack 和 Galera Cluster 在生产环境上部署了 1000 多个节点;
Galera 是一家位于芬兰赫尔辛基的小公司, 他们的产品可以用下面一张图来介绍;
基于 OpenStack 被大量使用, OpenStack 版本升级成为需要考虑的事, 不能影响生产环境, 要做到 0 停机时间;
OpenStack 实现了自己的滚动升级策略, 主要的思路是;
1. 表结构变更兼容: N 和 N+1 版本的服务同时支持 N+1 版本的一个中间状态的表结构, 如下;
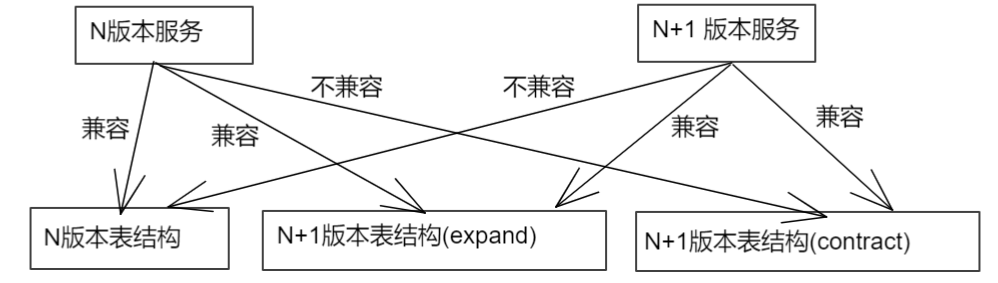
2. RPC 调用兼容: 类似表结构, RPC调用也做了兼容;
3. 服务之间的调用兼容: 服务之间的 restful 调用通过版本号控制, http://restful-api/v2, http://restful-api/v3;
这里举例说下第1点—表结构变更的支持:
假如有一张表, 有3个属性:
用户名,
特长,
性别;
N版本插入了这样一条数据:
用户名: 吴艺凡,
特长: 牙签,
性别: 男;
N+1 版本想删除属性 “性别”, 流程大概是这样的;
1. N+1 的 expand 阶段不删除列, 但是服务不会再操作 “性别” 这一列;
这个时候 N 版本仍旧可以对表进行增删改查操作;
2. 逐步下线 N 版本的服务, 上线 N+1 版本的服务;
3. 变更表为 contract 阶段, 这个时候删除 “性别” 列;
如果场景不是删除列而是增加列, 则 N+1 版本的服务在 contract 阶段会用两种方法填充新列:
1. 服务在访问表时触发对列数据的填充;
2. 执行 contract 迁移的时候对列数据填充;
上面就是简单的表结构变更流程;
OpenStack 的滚动升级策略大概是从 Newton 版本开始的, 时间是在 2016年;
离开 OpenStack, 我们讲一下 Google;
2013年, Google 的分布式数据库 F1 取得成功, Google 发布了几篇关于分布式数据库的论文; 论述了 F1 的原理;
后来的很多分布式数据库都是以 Google 的论文作为基础开发出来的;
Google的其中一篇论文讲述了数据库升级时, 表结构变更的场景:
“Online, Asynchronous Schema Change in F1” — F1 中的在线, 异步表结构变更;
Google论文原文链接: http://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/41376.pdf
因为某种原因打不开, 您可以自行搜索一下 PDF 版;
Google F1 的背景就不讲了, 它是一个 分布式数据库, 解决传统 MySQL 和 Oracle 的问题; 这里稍微讲一下为什么需要在线表结构变更:
传统数据库在表结构变更时, 操作期间数据库无法提供服务;
即使有很多服务做热备, 但是数据库升级时服务不能访问数据库, 所以服务不可用;
Google 的论文可以保证在表结构变更期间, 服务仍然可以访问数据库;
以增加表字段为例, 大体上讲讲这篇论文:
如果要增加一个主键列, 列状态需要有如下的状态变更流程:
absent –> delete only –> write only –(db reorg)–> public
不存在 –> 只能被删 –> 只能被写 –重组数据–> 公共状态
这里的状态在论文的中 3.1 节有定义: 3.1 Schema elements and states;
比如: 一个 delete-only 的表或列, 不能被读, 只能被删, 一个 delete-only 的索引, 只能被删或者更新, 并且更新操作只能删除索引对应的键值对, 而不能创建;
A delete-only table, column, or index
cannot have their key–value pairs read by user transactions
and
1. if E is a table or column, it can be modified only by
delete operations.
2. if E is an index, it is modified only by delete and update
operations. Moreover, update operations can delete
key–value pairs corresponding to updated index keys,
but they cannot create any new ones.
下面是增删改表结构的流程, 其中红框部分是增加表字段的流程; 参见论文中的 Figure 3;
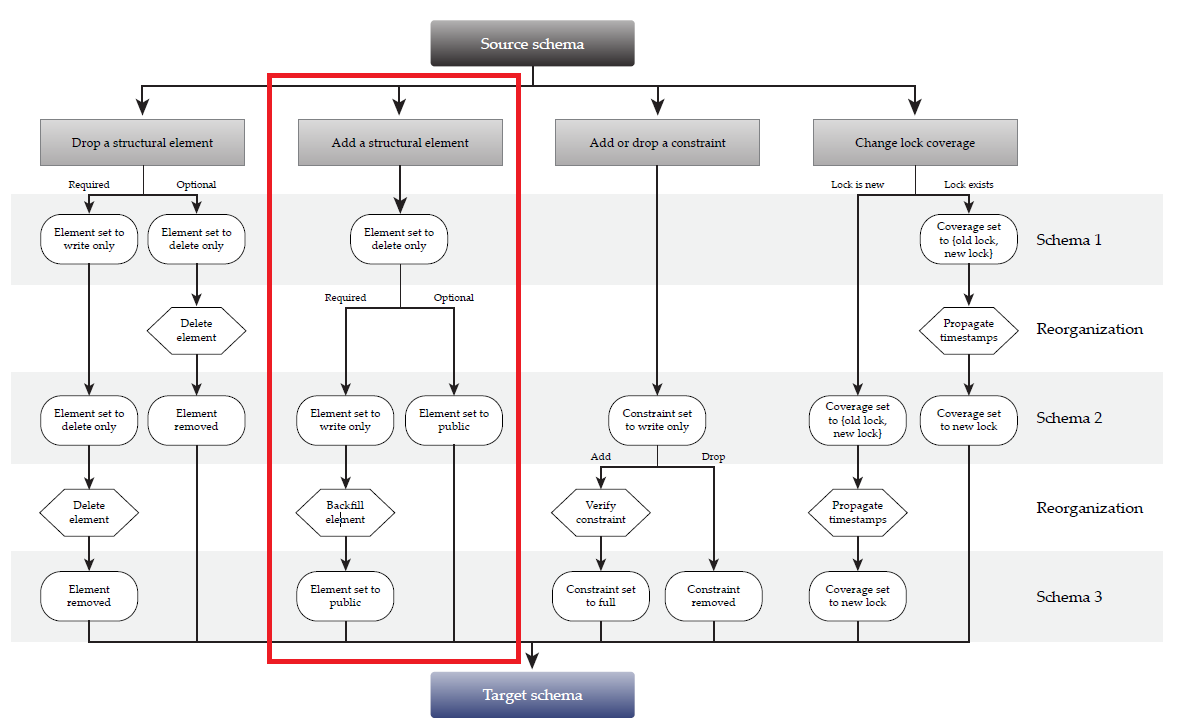
对于主键, 是上面提到的: absent –> delete only –> write only –(db reorg)–> public;
对于可选字段, 流程简单一点 absent –> delete only –(db reorg)–> public;
除了状态约束, 还加入了新的约束: lease(租期);
两个相邻的租期之间的操作是相容的;
以增加可选列为例;
absent –> delete only –(db reorg)–> public;
1. 计算节点1 在 t1 时间点同步到的列状态为absent;
2. t1+1 时间点列状态变为 delete only;
3. 计算节点2 的租期在 t1+2 过期, 它重新同步表状态, 获取的列的状态为 delete only;
4. 计算节点2 在 t1+3 时间点执行SQL: insert xxx into xxx, 新增加的列的状态为 delete only, 所以这列不会进入数据;
5. 计算节点1 在 t1+4 时间点 执行SQL: delete xxx from xxx, 它缓存的列状态为absent, 新列对它不可见, 它不需要删除新列的数据;
这个场景的关键点是 delete only 状态, 他可以保证 absent 状态的计算节点的操作不会留下orphan data(孤儿数据);
两个相邻的租期的计算节点的操作, 对于对方是兼容的;
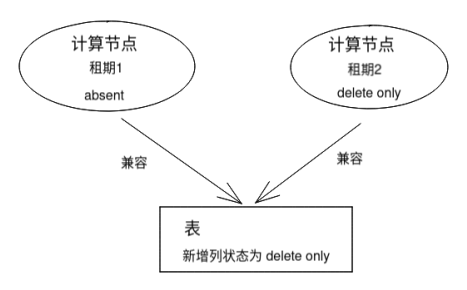
如果一个计算节点无法在租期过后重新同步表状态怎么办? 论文没提到, 其实很简单, 把这个计算节点杀掉就可以了;
我们再回头看看刚才 OpenStack 的滚动升级策略, 和 Google 的 这篇论文很像; 只是 OpenStack 把这种思想用在了业务服务的层面上;
完;