1. 算法原理
- 核心思想:未标记样本的类别,由距离其最近的k个邻居投票来决定。
- 已知条件:具有已标记数据集且知道数据集中每个样本所属类别。一个未标记数据样本。
- 目的:预测未标记数据样本所属类别。
- 算法原理伪代码:
- 假设 X_test 为待标记的数据样本,X_train为已标记的数据集
- 遍历 X_train 中所有样本,计算每个样本与 X_test 的距离,并把距离保存在 Distance 数组中
- 对 Distance 数组进行排序,取距离最近的 k 个点,记为 X_knn
- 在 X_knn 中统计每个类别的个数
- 待标记样本的类别就是在 X_knn 中样本个数最多的那个类别
- 优缺点:
- 优点:准确性高,对异常值和噪声有较高容忍度。
- 缺点:计算量较大,对内存需求大。(每次对未标记样本分类都需要重新计算距离)
- 算法参数:算法参数为 k ,参数选择根据数据来确定,k 值越大,模型偏差越大,对噪声数据越不敏感。(可能出现欠拟合)k值越小,模型方差越大。(可能出现过拟合)
2. 使用k-近邻算法进行分类
在sklearn中使用k-近邻进行分类处理的是sklearn.neighbors.KNeighborsClassifier类
#生成已标记数据
from sklearn.datasets import make_blobs
#生成数据
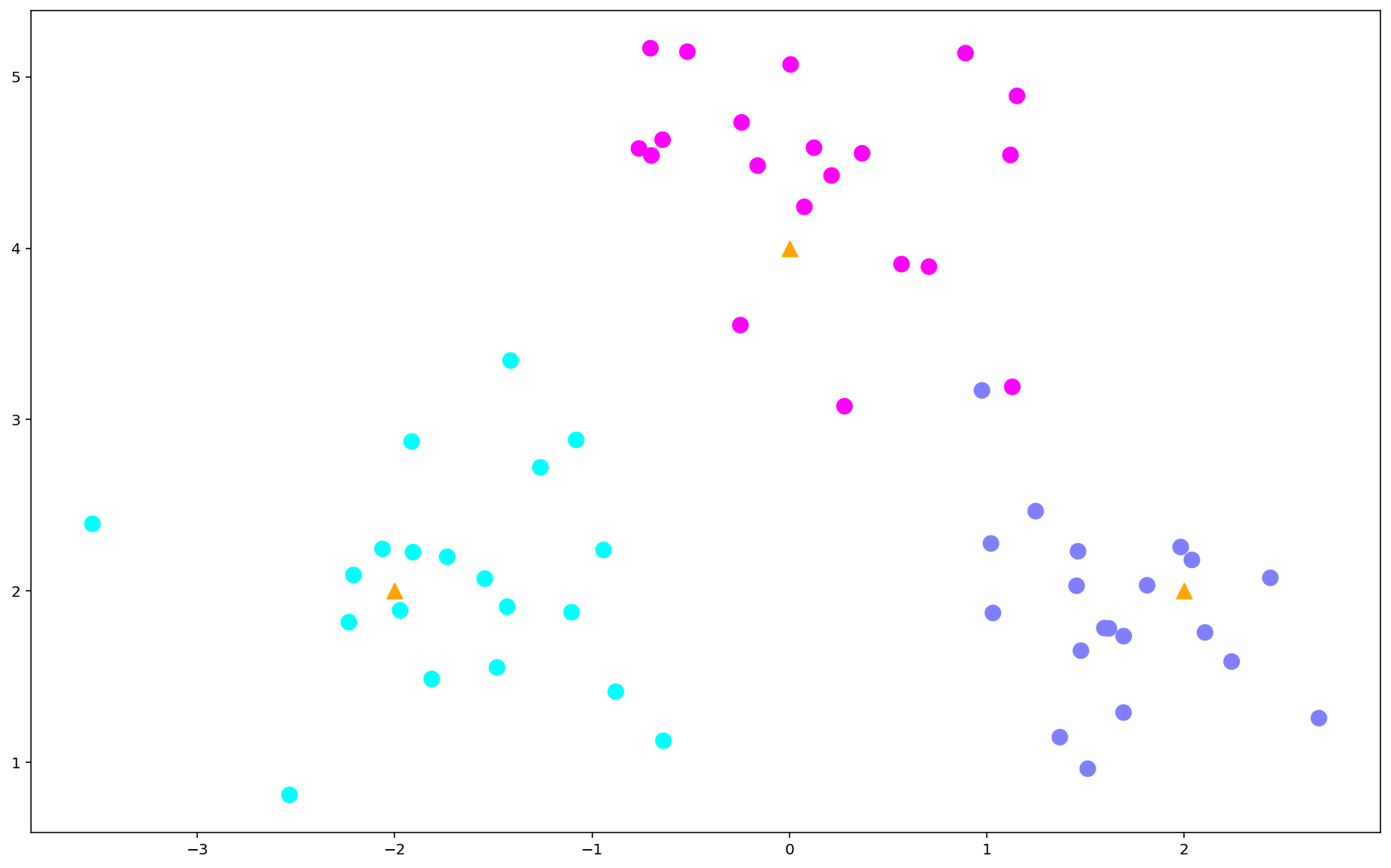
centers = [[-2,2],[2,2],[0,4]]
X,y = make_blobs(n_samples = 60,centers = centers,
random_state = 0,cluster_std = 0.6)
说明:n_sample为训练样本的个数,centers指定中心点位置,cluster_std指明生成点分布的松散程度(标准差)。训练数据集放在X中,数据集类别标记放在y中。
import matplotlib.pyplot as plt
import numpy as np
#绘制数据
plt.figure(figsize = (16,10),dpi = 144)
c = np.array(centers)
plt.scatter(X[:,0],X[:,1],c = y,s = 100,cmap = 'cool') #画样本
plt.scatter(c[:,0],c[:,1],s = 100,marker = '^',c = 'orange') #画中心点
<matplotlib.collections.PathCollection at 0x1f28e49d220>
使用KNeighborsClassifier来对算法进行训练,选择的参数是k=5
from sklearn.neighbors import KNeighborsClassifier
#模型训练
k = 5
clf = KNeighborsClassifier(n_neighbors = k)
clf.fit(X,y)
KNeighborsClassifier()
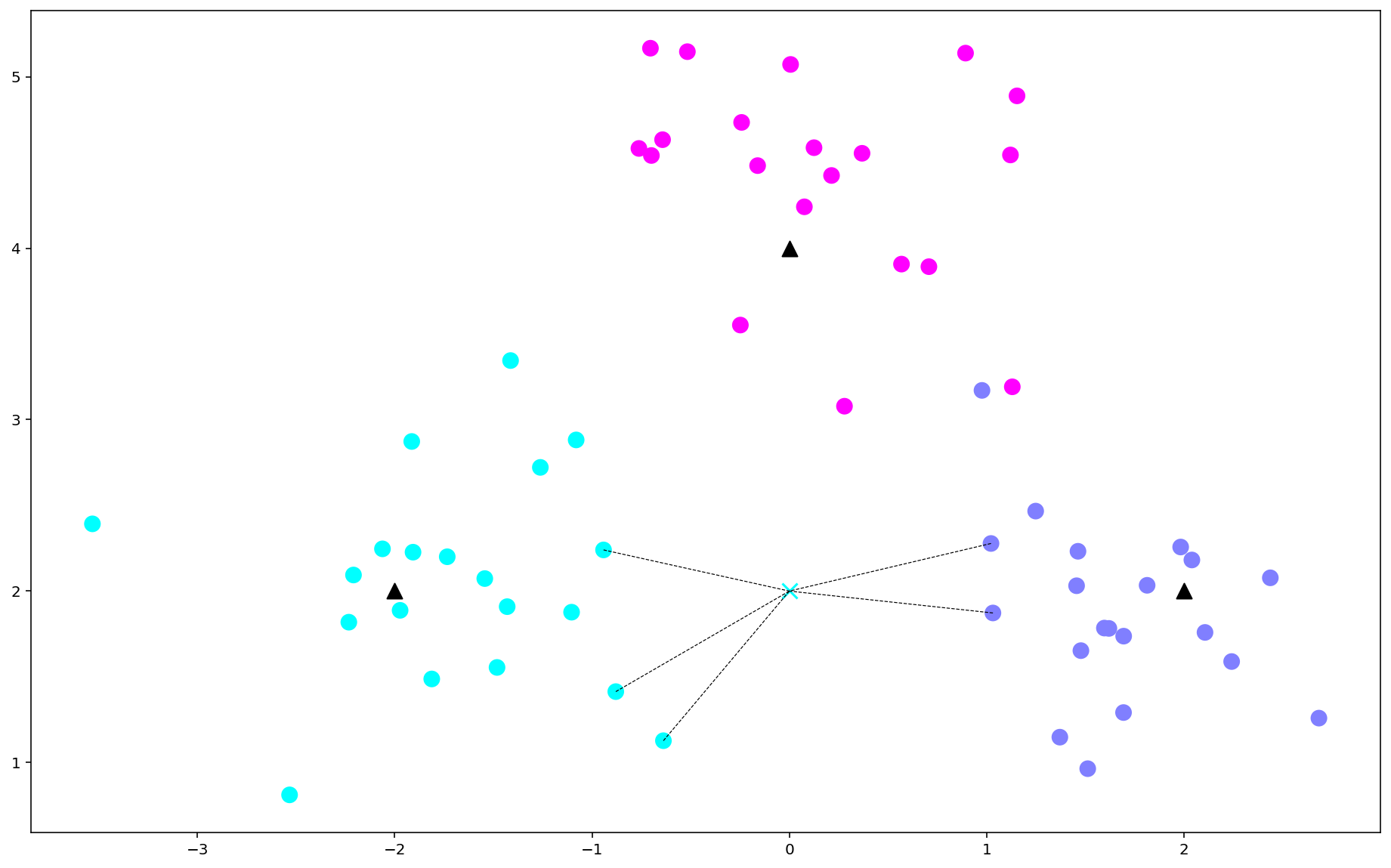
对一个新的样本进行预测,需要进行预测的样本为[0,2],使用kneighbors()方法把样本周围距离最近的5个点取出来,取出来的点是训练样本X中的索引。
#进行预测
X_sample = np.array([0,2]).reshape(1,-1)
y_sample = clf.predict(X_sample)
neighbors = clf.kneighbors(X_sample,return_distance = False)
X_sample
array([[0, 2]])
y_sample
array([0])
neighbors
array([[16, 20, 48, 6, 23]], dtype=int64)
标记最近的5个点和待预测样本
#画示意图
plt.figure(figsize = (16,10),dpi = 144)
plt.scatter(X[:,0],X[:,1],c=y,s = 100,cmap = 'cool') #样本
plt.scatter(c[:,0],c[:,1],s=100,marker = '^',c = 'k') #中心点
plt.scatter(X_sample[0][0],X_sample[0][1],marker='x',
c = y_sample,s = 100,cmap = 'cool') #待预测点
for i in neighbors[0]:
plt.plot([X[i][0],X_sample[0][0]],[X[i][1],X_sample[0][1]],'k--',linewidth = 0.6) #预测点与距离最近5点的连线
3. 使用k-近邻算法进行回归拟合
用k-近邻算法在连续区间内对数值进行预测,进行回归拟合。
在scikit-learn中,使用k-近邻算法进行回归拟合的算法是sklearn.neighbors.KNeighborsRegressor类
#生成数据集,在余弦曲线的基础上加入了噪声
import numpy as np
n_dots = 40
X = 5 * np.random.rand(n_dots,1)
y = np.cos(X).ravel()
#添加一些噪声
y += 0.2 * np.random.rand(n_dots) - 0.1
#使用KNeighborsRegressor来训练模型
from sklearn.neighbors import KNeighborsRegressor
k = 5
knn = KNeighborsRegressor(k)
knn.fit(X,y)
KNeighborsRegressor()
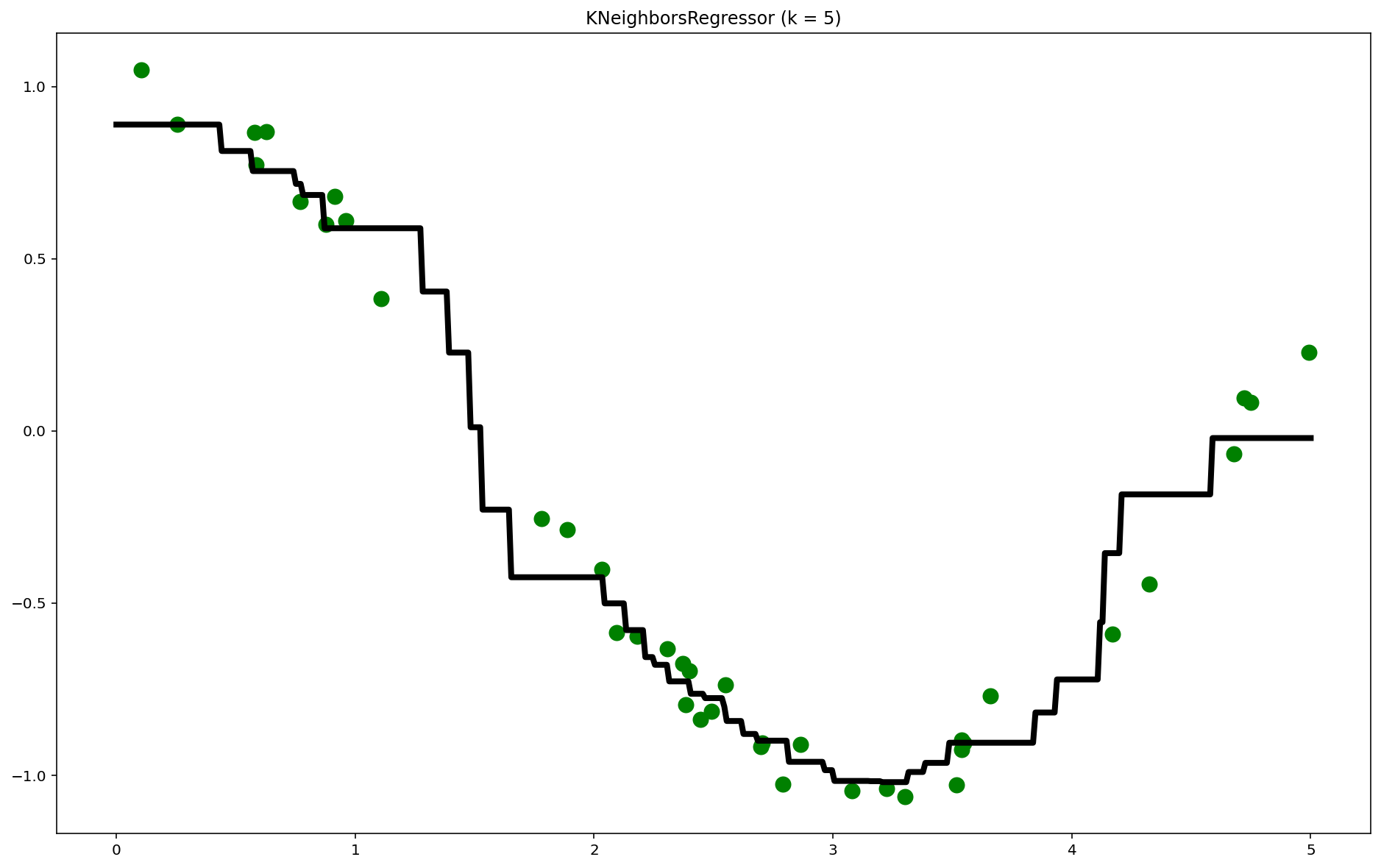
回归拟合的过程:在X轴上指定区间内生成足够多的点,针对这些足够密集的点,使用训练出来的模型进行预测,把所有的预测点连接起来得到拟合曲线。
#生成足够密集的点进行预测(np.newais用于插入新维度)
T = np.linspace(0,5,500)[:,np.newaxis]
y_pred = knn.predict(T)
knn.score(X,y)
0.9756908320045331
#绘制拟合曲线
plt.figure(figsize = (16,10),dpi = 144)
plt.scatter(X,y,c = 'g',label = 'data',s = 100) #画出训练样本
plt.plot(T,y_pred,c = 'k',label = 'prediction',lw = 4) #画出拟合曲线
plt.axis('tight')
plt.title('KNeighborsRegressor (k = %i)' % k)
plt.show()
4. 糖尿病预测
使用 k-近邻算法及其变种,对 Pima 印第安人的糖尿病进行预测。
#加载数据
import pandas as pd
data = pd.read_csv('diabetes.csv')
print('dataset shape {}'.format(data.shape))
data.head()
dataset shape (768, 9)
{ vertical-align: top }
.dataframe thead th { text-align: right }
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
- Outcome:0表示没有糖尿病,1表示有糖尿病。
8个特征分别如下:
- Pregnancies:怀孕的次数。
- Glucose:血浆葡萄糖浓度,采用2小时口服葡萄糖耐量试验测得。
- BloodPressure:舒张压(毫米汞柱)
- SkinThickness:肱三头肌皮肤褶皱厚度(毫米)
- Insulin:两个小时血清胰岛素(μU/毫升)
- BMI:身体质量指数,体重除以身高的平方。
- Diabetes Pedigree Function:糖尿病血统指数。糖尿病和家庭遗传相关。
- Age: 年龄
data.groupby("Outcome").size()
Outcome
0 500
1 268
dtype: int64
#将8个特征值分离出来作为训练数据集,把Outcome列分离出来作为目标值。
#然后把训练集划分为训练数据集和测试数据集
X = data.iloc[:,0:8]
Y = data.iloc[:,8]
print('shape of X {}; shape of Y {}'.format(X.shape,Y.shape))
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size = 0.2)
shape of X (768, 8); shape of Y (768,)
4.1 模型比较
使用普通的k-均值算法、带权重的k-均值算法以及指定半径的k-均值算法分别对数据集进行拟合并计算评分:
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
#构造3个模型
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors = 2)))
models.append(("KNN with weights",KNeighborsClassifier(
n_neighbors=2,weights = "distance")))
models.append(("Radius Neighbors",RadiusNeighborsClassifier(
n_neighbors=2,radius = 500.0)))
print(models)
#分别训练3个模型,并计算评分
results = []
for name,model in models:
model.fit(X_train,Y_train)
results.append((name,model.score(X_test,Y_test)))
for i in range(len(results)):
print("name: {};score: {}".format(results[i][0],results[i][1]))
[('KNN', KNeighborsClassifier(n_neighbors=2)), ('KNN with weights', KNeighborsClassifier(n_neighbors=2, weights='distance')), ('Radius Neighbors', RadiusNeighborsClassifier(radius=500.0))]
name: KNN;score: 0.7792207792207793
name: KNN with weights;score: 0.7077922077922078
name: Radius Neighbors;score: 0.6883116883116883
说明:
- 权重算法,选择了距离越近,权重越高。
RadiusNeighborsClassifier模型的半径,选择了500- 从输出看出,普通的k-均值算法性能还是最好。答案是不准确的,因为训练样本和测试样本是随机分配的,不同的训练样本和测试样本组合可能导致计算出来的算法准确性是有差异的。
如何更准确地对比算法准确性?多次随机分配训练数据集和交叉验证数据集,然后求模型准确性评分的平均值。scikit-learn提供了KFold和cross_val_score()函数来处理这种问题:
交叉验证具体流程:https://blog.csdn.net/qq_36523839/article/details/80707678
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name,model in models:
kfold = KFold(n_splits = 10)
cv_result = cross_val_score(model,X,Y,cv = kfold)
results.append((name,cv_result))
for i in range(len(results)):
print("name: {};cross val score: {}".format(
results[i][0],results[i][1].mean()))
name: KNN;cross val score: 0.7147641831852358
name: KNN with weights;cross val score: 0.6770505809979495
name: Radius Neighbors;cross val score: 0.6497265892002735
上述代码通过KFold把数据集分成10份,其中1份会作为交叉验证数据集来计算模型准确性,剩下9份作为训练数据集。
cross_val_score()函数总共计算出10次不同训练集和交叉验证数据集组合得到的模型准确性评分。
4.2 模型训练及分析
综上所述,普通的k-均值算法性能更优一些。接下来,我们就使用普通的k-均值算法模型对数据集进行训练,并查看对训练样本的拟合情况以及对测试样本的预测准确性情况。
knn = KNeighborsClassifier(n_neighbors = 2)
knn.fit(X_train,Y_train)
train_score = knn.score(X_train,Y_train)
test_score = knn.score(X_test,Y_test)
print("train score: {};test score: {}".format(train_score,test_score))
train score: 0.8159609120521173;test score: 0.7792207792207793
以上结果表明:
- 算法模型过于简单,无法很好拟合样本数据
- 模型准确性欠佳,预测准确性较低,需要进一步画学习曲线验证。
from sklearn.model_selection import ShuffleSplit
from common.utils import plot_learning_curve
knn = KNeighborsClassifier(n_neighbors = 2)
cv = ShuffleSplit(n_splits = 10,test_size = 0.2,random_state = 0)
plt.figure(figsize = (10,6),dpi = 200)
plot_learning_curve(plt,knn,"Learn Curve for KNN Diabetes",
X,Y,ylim = (0.0,1.01),cv = cv)
<module 'matplotlib.pyplot' from 'D:\Anaconda3\lib\site-packages\matplotlib\pyplot.py'>

如上图所示:训练样本评分较低,且测试样本与训练样本距离较大,这是典型的欠拟合现象。
4.4 特征选择及数据可视化
如果要用直观方法来揭示为什么k-均值算法不是针对这一问题的好模型?
- 将数据画出来,可具有8个特征,无法在这么高的维度中画出数据并直观观察
- 可以采用特征选择,即只选择2个与输出值相关性最大的特征,这样就可以在二维平面上画出输入特征值与输出值的关系。
scikit-learn在sklearn.feature_selection包中提供了丰富的特征选择方法,在此使用SelectKBest选择相关性最大的两个特征:
from sklearn.feature_selection import SelectKBest
selector = SelectKBest(k = 2)
X_new = selector.fit_transform(X,Y)
X_new[0:5]
array([[148. , 33.6],
[ 85. , 26.6],
[183. , 23.3],
[ 89. , 28.1],
[137. , 43.1]])
准确性效果
results = []
for name,model in models:
kfold = KFold(n_splits = 10)
cv_result = cross_val_score(model,X_new,Y,cv = kfold)
results.append((name,cv_result))
for i in range(len(results)):
print("name: {};cross val score: {}".format(
results[i][0],results[i][1].mean()))
name: KNN;cross val score: 0.725205058099795
name: KNN with weights;cross val score: 0.6900375939849623
name: Radius Neighbors;cross val score: 0.6510252904989747
由此看出两个特征与所有特征比较准确性差不多,侧面体现了SelectKBest特征选择的准确性。
#两个特征画出所有训练样本,观察分布情况
plt.figure(figsize = (10,6),dpi = 200)
plt.ylabel("BMI")
plt.xlabel("Glucose")
#画出Y==0的阴性样本
plt.scatter(X_new[Y==0][:,0],X_new[Y==0][:,1],c = 'r',s = 20,marker = 'o')
#画出Y==1的阳性样本
plt.scatter(X_new[Y==1][:,0],X_new[Y==1][:,1],c = 'g',s = 20,marker = '^')
<matplotlib.collections.PathCollection at 0x1f29282d520>
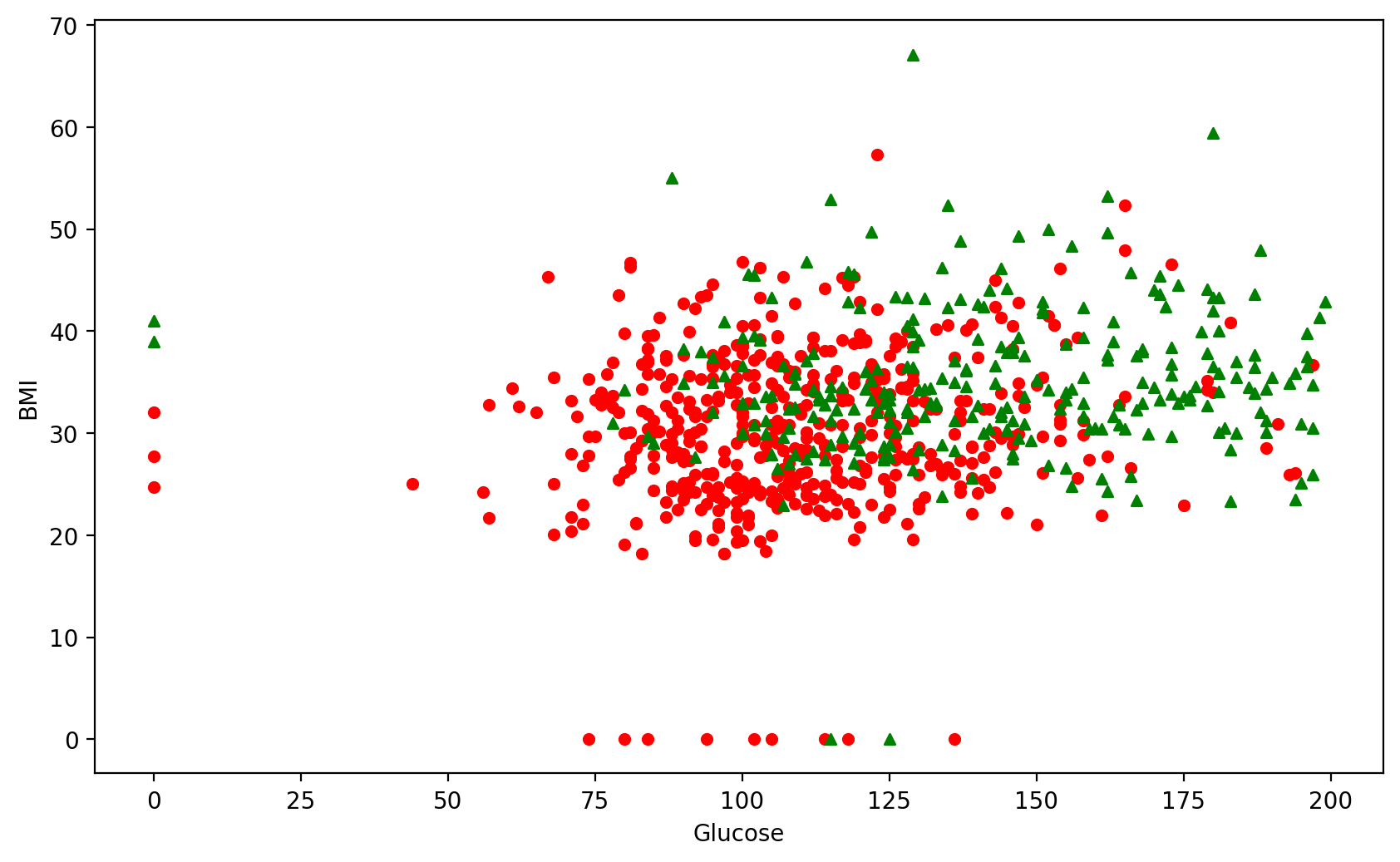
因为两特征对应的阴性和阳性样本的分类并不明显,所以很难预测糖尿病问题,无法达到很高的预测准确性。
Se você está se perguntando como descobrir se seu marido está traindo você no WhatsApp, talvez eu possa ajudar. Quando você pergunta ao seu parceiro se ele pode verificar seu telefone, a resposta usual é não.